
Stop Paying for 4 AI Models
Your "Council of Experts" is Just One Guy with 4 Hats

Have you heard of Dr. Derya Unutmaz, MD? He is a giant in the field of immunology, a professor at The Jackson Lab, and a full-paying subscriber to all 4 frontier models: ChatGPT, Gemini, Grok, and Claude. He uses them in tandem and found that each model has a distinct personality, strength, or perspective profile. They are his “Grand Council of AI Advisors.”
I couldn’t resist, so I warned him on Twitter that treating 4 AI models as a “Council of Experts” is dangerous because they essentially share the same underlying data and asset class (Transformers). The internet exploded. And by internet, I mean technicians and ML engineers energetically lectured about the “architectural nuances” of the red vs. blue Lego bricks. But while we debate the bricks, I worry the entire house sits crooked.
Let me go through the engineering argument, the economic rebuttal, and the actionable takeaway: Should you subscribe to all 4 AI services and ask your questions 4 times?
The Engineering Argument: 5 Critiques
To be fair, this is a sophisticated debate, so let me first give the engineers’ POV on why I am wrong. Strongest critiques are last.
Ensembling/Random Forest critique: “4 models together is called an ensemble… Random Forest performs better than a decision tree.” In traditional statistics, if you ask one model to predict a stock price, it might be wrong. If you ask 100 models and average their answers, the noise cancels out, and you get a more accurate number (aka, the Wisdom of Crowds). 4 AI models are like a crowd of 4 different people. Even if they aren’t perfect, the group average is statistically safer than just trusting one.
The Black Box critique: “The 4 models are trained differently and have different parameter settings.” Even if two AI models read the same books (training data), they wired their brains differently during the learning process. Therefore, they think differently.
The Instruction Tuning critique: “The 4 models annotate data differently.” Source material (pre-training) is just the starting point. The real behavior comes from how humans taught the model to behave (Fine-Tuning/RLHF). OpenAI’s human teachers are different from Anthropic’s human teachers. They think I’m ignoring the nurture side of the nature vs. nurture debate.
The “Temperature” and Non-Determinism critique: “LLMs have a Temperature setting (randomness).” Even the same model asked the same question twice can give different answers if the temperature is >0. Running the same model multiple times creates artificial diversity, effectively simulating a council.
The Reasoning Path Differences critique: “Different models use different tokenizers (how they chop up words) and different attention heads (what they focus on).” ChatGPT might focus on the legal aspect of a prompt, while Claude focuses on the ethical aspect, purely due to architectural quirks.
The Economic Rebuttal
First, let’s establish that all frontier models (ChatGPT, Gemini, Grok, Claude) consume the same massive datasets: Common Crawl (the internet), Wikipedia, GitHub, StackOverflow, and large curated datasets like The Pile. These sources dominate pretraining, and they encode the same statistical patterns, priors, and blind spots.1 When the four models inherit the same underlying corpus, their errors are correlated.
Key rebuttal point: You are confusing Variance with Bias.
Yes, ensembling reduces Variance (noise from syntax errors). If I ask 4 drunk guys the same question, their slurring averages out.
But it does not reduce Bias (systemic error from cognitive delusion). If all 4 drunk guys watched the same fake news channel last night, they’ll give you the same wrong answer, just with more confidence.
LLMs work the same way. If four models are trained on the same flawed internet consensus, they are not independent. Ensembling them produces a high-confidence hallucination (Narayana & Kapoor, 2024).2
Random Forests rely on uncorrelated trees. They force this by hiding features from each tree (feature bagging). You cannot “hide” the internet from ChatGPT or Claude. LLMs are trained to minimize loss across the entire corpus. They all converged on the same dominant patterns. The financial term is Correlation Risk.
Even the newest class of reasoning models, which spend inference time thinking before answering, are ultimately just traversing logic trees grown from the same seed data. They might be better at spotting syntax errors (reducing Variance), but because their reasoning priors are derived from the same training corpus, they are just as susceptible to the shared delusions of the internet (Systemic Bias).
Second, to the point that each model has its own secret sauce (different weights, different RLHF annotators, different temperature):
You are describing Idiosyncratic Risk. I am talking about Systemic Risk.
If your goal is “different flavors of Tabasco” (creative writing, brainstorming, coding syntax), then the idiosyncratic differences matter. But if you are using AI for epistemological tasks (find truth, analysis, fact-checking, economic logic), you are facing Systemic Risk.
You might assume that because ChatGPT and Claude are built by different companies, their mistakes would be random. The data shows the opposite. A 2025 study (Kim et al., 2025) measured exactly how often different models make the same error (the technical term for this is “error agreement rate”). The weakest models (low accuracy) are in the bottom left. The strongest frontier models (the ones you pay for and with the highest accuracy) are in the top right. The chart shows the weak models make random unrelated mistakes, but the frontier models make the exact same mistakes (high error agreement = Yellow). As models get bigger and smarter (i.e., ingest more of the same internet), they converge on the same specific delusions.
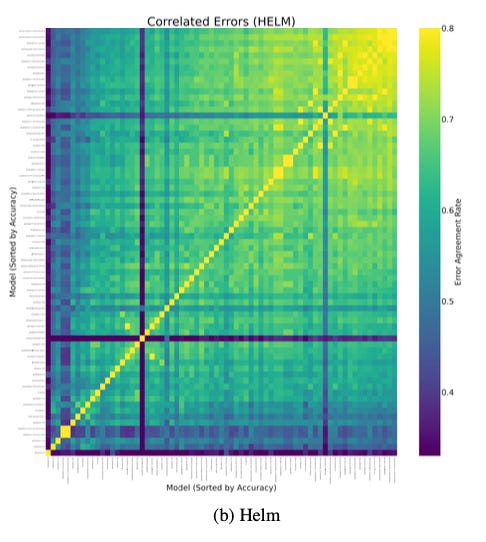
This craziness is because the frontier models are trying to “compress” the human knowledge contained in the massive datasets. Anthropic’s research on Transformer Circuits (Elhage et al., 2021) explains this capacity problem. Models have limited parameters (brain space) to store infinite facts. To fit it all in, they sometimes need to store unrelated concepts in the same box — like when my movers used my running socks as padding for my cologne collection. If you ask a prompt that touches that box, the model might accidentally unpack the wrong concept. When the four models inherit the same underlying corpus and compression constraints, their errors are systemic.
Yes, OpenAI and Anthropic use different human labelers. This is like saying a Harvard grad and a Yale grad have diverse perspectives. Sure, their professors were different, but they read the same textbooks, come from the same socio-economic class, and share the same Western-centric worldview. RLHF changes the style of the answer (i.e., the personality), but it does not change the epistemological limit of the underlying data.
Different weights, reasoning paths, and architectural quirks might make ChatGPT and Gemini focus on different aspects of the prompt. That is useful for framing, but not for fact-checking. Remember when the entire internet believed “Housing prices never go down,” circa 2007? If the underlying training data contains a false correlation, every model will find that pattern and predict continued appreciation. They might explain it differently, but the hallucination is shared.
Another example: imagine you are using AI as a tax accountant, but if the tax law book they are reading is outdated (systemic bias in training data), they will all still file your return incorrectly. Don’t ask me how I know this.
Regarding the temperature argument: Randomness is not insight. Rolling the dice multiple times on fundamentally flawed data doesn’t generate truth.
Takeaway: Are 4 Models Worth Your Time?
Hiring 4 AI models is like hiring 4 McKinsey consultants who all read the same Wikipedia articles.
You don’t have diversification, and you have quadrupled your personal burn rate for the privilege.
LLMs are a monoculture forest, grown from the same soil (Internet Data), cloned from the same genes (Transformers), and pruned by the same shears (RLHF). They are correlated assets, and correlated assets don’t hedge each other.
In 2008, banks also argued their assets were “nuanced” and “diversified.” It turned out they were just repackaging the same subprime risk.
When you’re using LLMs as sources of truth, the underlying data matter far more than the architecture. Pick one model, double-check its work, and save the other $60 a month.
This simplification ignores proprietary licensed data, specialized corpora, retrieval-augmented systems, and recent post-cutoff updates each provider may incorporate. The frontier models use grounding mechanisms, that allow a model find answers outside of its memory (parameter weights). Think about it like an open book test: grounding lets the model query a reference document (RAG), search the web, or use a calculator (Python code execution). Those differences matter for freshness and coverage, but they do not meaningfully reduce systemic correlation in the underlying statistical priors learned during pretraining. OpenAI’s OG-paper on “Scaling Laws” showed that performance improves primarily with model size, dataset size, and compute budget, while the influence of other architectural hyperparameters is comparatively weak.
Narayanan & Kapoor at Princeton University have cataloged examples where different models hallucinate the exact same falsehood because the underlying web corpus encoded the same mistake.
Not a rebuttal, but some thoughts for consideration
* Calling out that they all use the same underlying 'asset' (i.e. transformer architecture) as a point of consideration is kind of like calling out "they all speak the same language - English".
This point is a bit weaker than you may think; *nearly* any idea that can be represented in the spoken language can *potentially* be discovered by transformers. So, on a certain level, it's a weakness only in the absolute sense, not a practical sense.
* Your point about coming from the same training corpus is likewise weaker than you may think, since the training corpus includes *radically different points of view* that bring totally different methods of evaluation and vectors of thought to the table. These different methods of thought, can be applied and alchemized together in different ways, in different orders, with different levels of emphasis, to generate wildly different final analysis, and it's the domain / model specific 'secret sauce' that determines how good those alchemizations actually are. In this way, I feel your point is perhaps being overstated.
* However, I think if we combine those two points of concern, they do hint (indirectly) something real that supports your theorem!
Late 19th and early 20th century Economic theory, in the English speaking world, was a vast and robust field of research many different schools that had a wealth of nuances and substantive differences, sort of like how I described the modern LLM space above, yes?
And yet, there were powerful and subsequently transformative schools of economic thought that were *only being expressed in German*; the Austrian school stuff of Von Mises and Hayek. They *could* have been expressed in English, but no one was doing so. They had to translate and carry their ideas to the English speaking world for them to resonate.
(And for any ML folks reading this: yes, I’m deliberately oversimplifying.
I’m glossing over major architectural differences between models, overstating the theoretical discoverability of ideas in transformer space, and ignoring the very non-uniform representation of viewpoints in the training distribution. All true.
But none of those caveats really change the overall point. =p)
This article is a fresh air in the crowded space.
Pure joy to read those how go against the flow.
Thanks a lot. re-read 3 times.